
Többléptékű fúziós altér-klaszterezés hasonlósági megkötés használatával
Ahogy egyre több adattal kell dolgoznunk, úgy növekszik a különféle algoritmusok számítási ideje. Mivel egyre több helyen foglalkoznak egyre nagyobb mennyiségű adat klaszterezésével, természetes, hogy egyre jobban teljesítő módszerekre van szükség, ha nem akarjuk évekig tanítani a modellünket.
Az egyik ilyen nagy előrelépés az altér-klaszterező algoritmusok kidolgozása volt, mint például a CLIQUE vagy a MAFIA, amelyek egy altéren klasztereztek, jelentősen csökkentve ezzel az egyes klasztereket meghatározó dimenziók, és így a felhasznált adatok mennyiségét (és ezáltal a futásidőt) is.
Egy új kutatás azonban arra hívja fel a figyelmet, hogy ezen módszerek alapfeltevése, miszerint a nyers adat alacsony-dimenziós lineáris alterek egy uniójában rejlik, a valóságban túl szigorú, emiatt pedig nehéz generalizálni ezeket a módszereket. Erre a problémára kínál megoldást a mély autoenkódereken (DAE – Deep AutoEncoder) alapuló mély altér-klaszterezés, viszont a korábbi módszerek nem vették figyelembe a DAE-ban beágyazódott többskálás információt.
Ezen a felismerésen alapul a „Több léptékű fúziós altér-klaszterezés hasonlósági megkötés használatával” nevű módszer (aminek még a rövidítése – SC-MSFSC, mint „Multi-Scale Fusion Subspace Clustering Using Similarity Constraint” – sem egyszerű).
A módszer több részből áll, vegyük is sorra mindet!

Az alapötlet ábrázolása.
Jellemző-kivonás (~Feature extraction)
Első körben a jellemzők keresése történik meg, amely során egy konvolúciós DAE-t vettek alapul a kutatók. Ennek a segítségével az altér-klaszterezéshez alkalmas látens altérbe (ami az adatok egy olyan reprezentációja, ahol a tömörített adatot úgy tároljuk, hogy a hasonló pontok közelebb legyenek egymáshoz) vetítették, azaz inputból (X) az encoder segítségével megkapták a látens változót (Z) majd ezt átküldték a dekóderen, hogy visszakapják az input rekonstrukcióját (X ̂), a loss pedig:
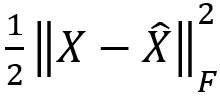
Ennek segítségével biztosították, hogy a Z teljes mértékben reprezentálni tudja az inputot.
2. Self-expression modul
Ennek a modulnak a segítségével kapjuk meg az „önkifejezési mátrix”-ot, amelynek a lényege, hogy a teljes adathalmazt az adat-vektorainak egy kis részhalmazával reprezentáljuk. Az eredmény egy olyan C koefficiens-mátrix lesz, hogy valamilyen Z adatmátrixra Z = CZ, C pedig egy diagonális és négyzetes mátrix (ezt pedig úgy érik el, hogy a modul loss-függvénye a self-expression-kifejezésen túl egy regularizációt is tartalmaz).
3. Többskálás fúziós modul
Ez a modul arra szolgál, hogy egyesítse az előző lépésben megkapott koefficiens-mátrixot az encoder-ben lévő konvolúciós rétegekkel. Itt történik a varázslat – ahogy korábban már említettem, a DAE-ben tárolt adatot a klasszikus altér-klaszterező modellek nem használják, itt viszont pontosan ebben a lépésben válnak hasznossá. Ahhoz, hogy ez megtörténjen, a szerzők általánosították mind a loss-, mind a self-expression-függvényt, méghozzá úgy, hogy összegezték minden réteg egyéni függvényét (tehát a loss-függvény például:
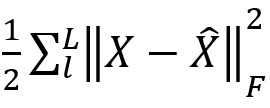
ahol l = 1, ..., L és L a konvolúciós rétegek száma). Ezáltal a látens változókat tartalmazó mátrixok megkapták a DAE-ban kódolt többskálás információt is! Minél kisebb a koefficiens-mátrix, annál egyszerűbb (pl. pixel-szintű) információt tárol, minél nagyobb, annál bonyolultabbat.
Mivel ugye a koefficiens-mátrixok különböző skálájúak, nagy kihívás volt összekombinálni ezeket. A szerzők elvetik mind a sima stack-elést, mind egy közös koefficiens-mátrix használatát, és azt ajánlják, hogy egy konvolúciós kernellel egyesítsük az egymásra stack-elt koefficiens-mátrixokat (és végül nyilván a self-expression loss-hoz is ezt a formáját használták a koefficiens-mátrixnak).
4. Hasonlósági megkötési modul
Ennek a modulnak a célja végül pedig az, hogy felügyelje a koefficiens-mátrixot – mivel a self-expression modul zajos lesz, egy küszöbölési módszer segítségével stabilizálták a tréninget. Ennek a lényege, hogy α 0 és 1 közötti küszöböt használva csak azokat az oszlopokat tarjuk meg, ahol az oszlop összegzése α, és a többi bejegyzést kinullázzuk. Az így kapott stack-elt zajtalanított koefficiens-mátrixot átlagoljuk, és ezt használjuk a koefficiens-mátrix tanításának felügyelésére úgy, hogy a hasonlósági megkötés a zajtalanított- és a(z előző lépésben kapott) fúziós koefficiens-mátrix különbségének Frobenius-normájának a négyzete lesz. Ezáltal a fúziós koefficiens-mátrix nemcsak ritka lesz, de megtartja egy részét annak az információnak is, ami a zajtalanítás során elveszett.
Összességében tehát a modell így néz ki:

A módszer, bár nem egyszerű, elképesztő jól teljesít: A Yale B adathalmazon például az összes eddigi altér-klaszterező módszert lepipál:

Forrás: Multi-Scale Fusion Subspace Clustering Using Similarity Constraint, Zhiyuan Dang, Cheng Deng, Xu Yang, Heng Huang; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 6658-6667